

Al proporcionar una gran cantidad de datos como un conjunto de entrenamiento, las computadoras ya son capaces de tomar decisiones y aprender de forma autónoma. Por lo general, la IA se lleva a cabo junto con el aprendizaje automático, el aprendizaje profundo y el análisis de big data. A lo largo de la historia de la IA, la principal limitación fue la potencia computacional, la banda cpu-memory-gpu y los sistemas de almacenamiento de alto rendimiento. El aprendizaje automático requiere una inmensa potencia computacional con una ejecución inteligente de comandos que mantiene a los procesadores y gpus en una utilización extremadamente alta, sostenido durante horas, días o semanas. En este artículo discutiremos las diferentes alternativas para estos tipos de cargas de trabajo. Desde entornos en la nube como Azure, AWS, IBM o Google hasta implementaciones on-premise con contenedores seguros que se ejecutan en Red Hat OpenShift y con IBM Power Systems.
Antes de ejecutar un modelo de IA, hay algunas cosas a tener en cuenta. La elección de herramientas de hardware y software es igualmente esencial para los algoritmos para resolver un problema en particular. Antes de evaluar las mejores opciones, primero debemos comprender los requisitos previos para establecer un entorno de ejecución de IA.
¿Cuáles son los requisitos previos de hardware para ejecutar una aplicación de IA?
- Alta potencia informática (GPU puede encender el aprendizaje profundo hasta 100 veces más que las CPU estándar)
- Capacidad de almacenamiento y rendimiento del disco
- Infraestructura de red (a partir de 10 GB)
¿Cuáles son los requisitos previos de software para ejecutar una aplicación de IA?
- Sistema operativo
- Entorno informático y sus variables
- Bibliotecas y otros binarios
- Archivos de configuración
Como ahora conocemos los requisitos previos para establecer una configuración de IA, vamos a profundizar en todos los componentes y las mejores combinaciones posibles. Hay dos opciones para configurar una implementación de IA: en la nube y local. Ya te dijimos que ninguno de ellos es mejor, ya que depende de cada situación.


Infraestructura en la nube
Algunos servidores tradicionales famosos en la nube son
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud Platform (GCP)
- IBM Cloud
Además de estos, existen nubes especializadas para el aprendizaje automático. Estas nubes específicas de ML proporcionan soporte de GPU en lugar de CPU para mejores entornos de computación y software especializados. Estos entornos son ideales para cargas de trabajo pequeñas en las que no hay datos confidenciales o confidenciales. Cuando tenemos que subir y descargar muchos TB de datos o ejecutar modelos intensivos durante semanas a la vez, poder reducir estos tiempos a días u horas y hacerlos en nuestros propios servidores nos ahorra muchos costes. Hablaremos de esto a continuación.
Servidores locales e implementaciones de plataforma como servicio (PAaS)
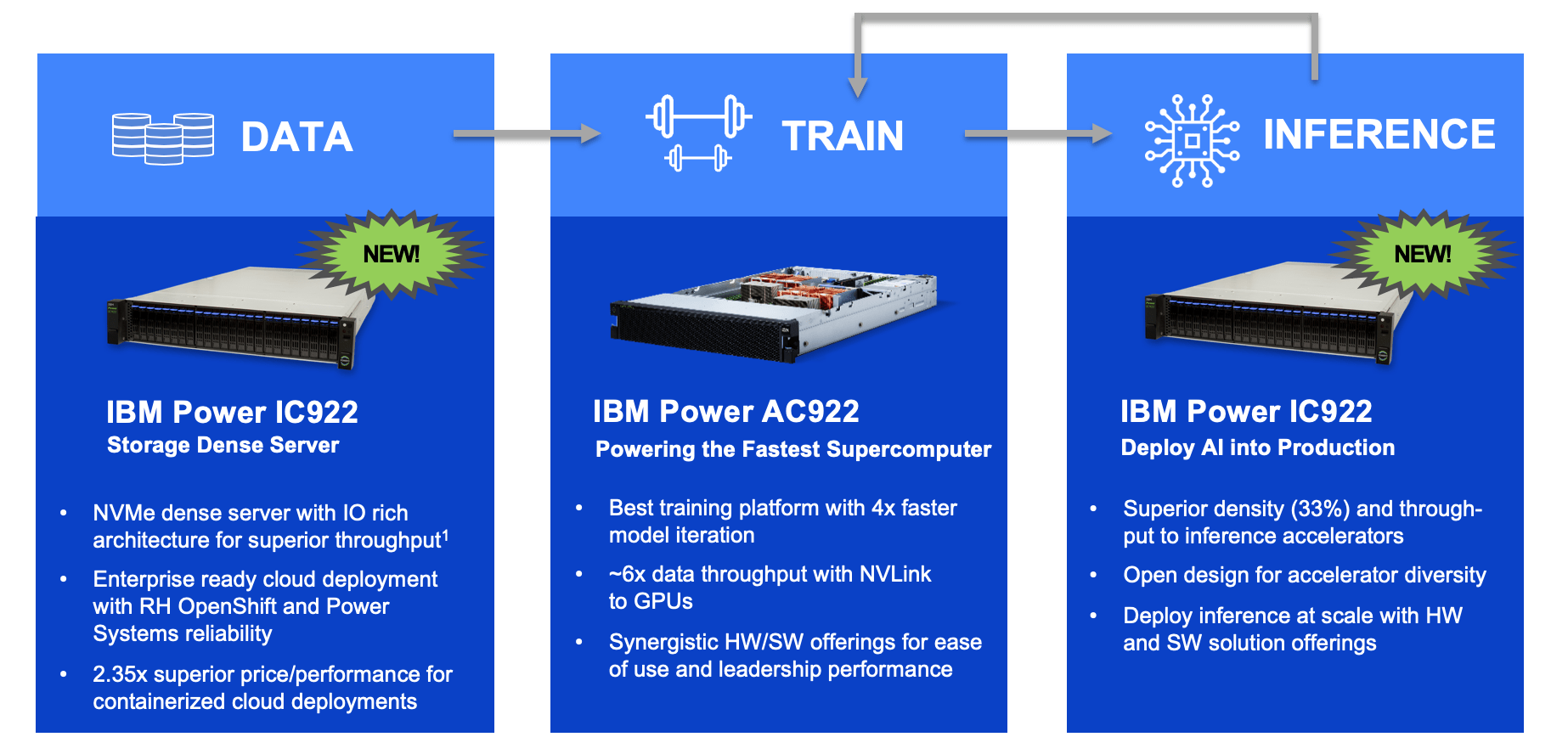
Se trata de servidores especializados presentes en las instalaciones de trabajo de una empresa de IA. Muchas empresas proporcionan servidores de IA altamente personalizados y construidos desde cero en el mundo. Por ejemplo, AC922 e IC922 de IBM son perfectos para la configuración de IA local.
Las empresas eligen como deben considerar el crecimiento futuro y el equilibrio entre las necesidades actuales y los gastos de los dos anteriores. Si su empresa es sólo un startup, los servidores de IA en la nube son los mejores porque esta opción puede eliminar la preocupación de las instalaciones a precios de alguna manera asequibles. Pero si su empresa crece en número y más científicos de datos se unen, la computación en la nube no aliviará sus cargas. En este caso, los expertos en tecnología hacen hincapié en la infraestructura de IA local para mejorar la seguridad, la personalización y la expansión.
LEA TAMBIÉN: Implemente su nube híbrida para ML y DL
Elegir la mejor arquitectura HW
Casi todas las plataformas de servicios en la nube ahora ofrecen el cálculo compatible con GPU, ya que la GPU tiene casi 100 veces más potente que la CPU promedio, especialmente si el aprendizaje automático se trata de visión por ordenador. Pero el verdadero problema es el caudal de datos entre el nodo y el servidor en la nube, sin importar cuántas GPU estén conectadas. Es por eso que la configuración de IA in situ tiene más votos, ya que el flujo de datos ya no es un gran problema.
El segundo punto a considerar es el ancho de banda entre LAS GPU y las CPU. En arquitecturas tradicionales como Intel, este tráfico se transfiere a través de canales PCI. IBM desarrolló un conector llamado NVLink,para que las GPU de la tarjeta NVidia y los núcleos Power9 pudieran comunicarse directamente sin capas intermedias. Esto multiplica el ancho de banda, que ya es más de 2 veces mayor entre el procesador y la memoria. Resultado: ¡no más cuellos de botella!


Como hemos señalado anteriormente los requisitos previos de software para ejecutar aplicaciones de IA, ahora tenemos que considerar el mejor entorno de software para un rendimiento óptimo de la IA.
¿Qué arquitectura de centro de datos es mejor para AI/DL/ML?
Mientras se hablaba de servidores con respecto a la infraestructura de IA, el diseño tradicional era la virtualización; es una distribución simple de los recursos de cálculo bajo sistemas operativos separados. Llamamos a cada entorno de sistema operativo independiente una “máquina virtual”. Si necesitamos ejecutar aplicaciones de IA en máquinas virtuales, nos enfrentamos a varias restricciones. Uno es los recursos necesarios para ejecutar todo el sistema, incluidas las operaciones del sistema operativo y las operaciones de IA. Cada máquina virtual requiere recursos de almacenamiento y computación adicionales. Además, no es fácil transferir un programa en ejecución en una máquina virtual específica a otra máquina virtual sin restablecer las variables de entorno.
¿Qué es un contenedor?
Para resolver este problema de virtualización, el concepto “Contenedor” salta. Un contenedor es un entorno de software independiente bajo un sistema operativo estándar con un entorno de tiempo de ejecución completo, una aplicación de IA y un archivo de dependencias, bibliotecas, archivos binarios y configuraciones reunidos como una sola entidad. La contenedorización ofrece ventajas adicionales a medida que las operaciones de IA se ejecutan directamente en el contenedor y el sistema operativo no tiene que enviar cada comando cada vez (guardar instancias de flujo de datos masivas). En segundo lugar, pero no menos, es relativamente fácil transferir un contenedor de una plataforma a otra plataforma, ya que esta transferencia no requiere cambiar las variables ambientales. Este enfoque permite a los científicos de datos centrarse más en la aplicación que en el entorno.
RedHat OpenShift Container Platform
El mejor software de contenedorización integrado en Linux es OpenShift Container Platform de Red Hat (un PAaS On-prem) basado en Kubernetes. Sus fundamentos se basan en contenedores CRI-O, mientras que Kubernetes controla la gestión de la contenedorización. La última versión de Open Shift es 4.7. La principal actualización proporcionada en OpenShift 4.7 es su relativa independencia de Docker y una mejor seguridad.
Operador NVIDIA GPU para contenedores Openshift
NVIDIA y Red Hat OpenShift se han unido para ayudar en la ejecución de aplicaciones de IA. Al usar GPU como procesadores de alta computación, el mayor problema es virtualizar o distribuir la energía de las GPU en los contenedores. NVIDIA GPU Operator for Red Hat Openshift es un Kubernetes que media la programación y distribución de los recursos de GPU. Dado que la GPU es un recurso especial en el clúster, requiere que se instalen algunos componentes antes de que las cargas de trabajo de la aplicación se puedan implementar en la GPU, estos componentes incluyen:
- Controladores NVIDIA
- tiempo de ejecución específico para kubernetes
- contenedor de dispositivo plugin
- reglas de etiquetado automático de nodos
- comproyentes de monitoreo


Los casos de uso más utilizados que utilizan GPU para la aceleración son el procesamiento de imágenes, la audición por computadora, la IA conversacional mediante PNL y la visión por ordenador mediante redes neuronales artificiales.
Entorno informático para el aprendizaje automático
Existen varios entornos informáticos de IA para probar/ejecutar aplicaciones de IA. En primer lugar, Tensorflow, Microsoft Azure, Apache Spark y PyTorch. Entre ellos, Tensorflow (Creado por Google) es elegido por la mayoría. Tensorflow es una plataforma de código abierto de extremo a extremo de grado de producción que tiene bibliotecas para el aprendizaje automático. La unidad de datos principal utilizada en TensorFlow y Pytorch es Tensor. Lo mejor de TensorFlow es que utiliza gráficos de flujo de datos para las operaciones. Es como un diagrama de flujo, y los programas realizan un seguimiento del éxito y el fracaso de cada flujo de datos. Este enfoque ahorra mucho tiempo al no volver a la línea base de una operación y prueba otros sub modelos si se produce un error en un flujo de datos.
Hasta ahora, hemos discutido todas las opciones para establecer una infraestructura de IA, incluyendo hardware y software. No es fácil seleccionar un producto específico que alberga todos los componentes deseados del sistema de IA. IBM ofrece componentes de hardware y software para la investigación y el desarrollo de IA eficientes y rentables como IBM Power Systems e IBM PowerAI, respectivamente.
IBM Power Systems
IBM Power Systems tiene componentes flexibles y basados en necesidades para ejecutar un sistema de IA. IBM Power Systems ofrece servidores acelerados como IBM AC922 e IBM IC922 para entrenamiento de ML e inferencia de ML,respectivamente.

IBM PowerAI
IBM PowerAI es una plataforma inteligente de ejecución de entornos de IA que facilita el aprendizaje profundo eficiente, el aprendizaje automático y las aplicaciones de IA mediante la utilización de IBM Power Systems y las GPU NVidia de toda la potencia. Proporciona muchas optimizaciones que aceleran el rendimiento, mejoran la utilización de recursos, facilitan la instalación, personalización y evitan problemas de administración. También proporciona marcos de aprendizaje profundo listos para usar como Theano, Bazel, OpenBLAS, TensorFlow,Caffe-BVLC o IBM Caffe.


Cuál es el mejor servidor para implementaciones locales. Comparemos IBM AC922 e IBM IC922
Si necesita servidores que puedan soportar cargas de aprendizaje automático durante meses o años sin interrupción, funcionando a un alto porcentaje de carga, los sistemas Intel no son una opción. Los sistemas NVIDIA DGX también están disponibles, pero como no pueden virtualizar GPU, cuando se desea ejecutar varios modelos de aprendizaje diferentes, hay que comprar más tarjetas gráficas, lo que las hace mucho más caras. La elección del servidor adecuado también dependerá del presupuesto. Los IC922 (diseñados para la inferencia de IA y las cargas de trabajo linux de alto rendimiento) son aproximadamente la mitad del precio de los AC922 (diseñados para la formación de conjuntos de datos de IA), por lo que para proyectos pequeños pueden ser perfectamente adecuados.


Si está interesado en estas tecnologías,
solicite una demostración
sin compromiso. Tenemos programas donde podemos asignarte un servidor completo durante un mes para que puedas probar directamente las ventajas de esta arquitectura de hardware.