
Cómo aprender Ceph | La realidad que NADIE cuenta
“Lanzo comandos pero no entiendo nada”. “Leo la documentación pero cuando algo falla no sé ni por dónde empezar”. “Llevo un año con Ceph y siento que apenas rasco la superficie”. Si alguna de estas frases te resuena, no estás solo. Y lo más importante: no es culpa tuya.
Después de más de 10 años trabajando con Ceph en producción, enseñando a cientos de administradores, y rescatando clusters “imposibles” a las 3AM, hemos llegado a una conclusión que nadie te dirá en las certificaciones oficiales: Ceph es brutalmente difícil de dominar. Y no porque seas mal administrador, sino porque la tecnología es intrínsecamente compleja, está en evolución constante, y la documentación asume conocimientos que nadie te enseñó explícitamente.
No te vamos a vender un “aprende Ceph en 30 días”. Queremos contarte la verdad sobre cómo se aprende realmente, cuánto tiempo toma, qué malentendidos te van a frenar, y cuál es la ruta más efectiva para pasar de lanzar comandos a ciegas a tener expertise real ;)
Por qué Ceph es tan difícil de aprender (y no es tu culpa)
La complejidad no es accidental: es inherente
Ceph no es “otro sistema de almacenamiento”. Es una arquitectura distribuida masivamente que debe resolver simultáneamente:
- Consistencia en escritura con replicación multi-nodo y consenso distribuido
- Disponibilidad continua ante fallos de hardware (discos, nodos, racks completos)
- Rebalanceo automático de petabytes de datos sin downtime
- Performance predecible bajo cargas variables y multi-tenant
- Tres interfaces completamente diferentes (block, object, filesystem) sobre la misma base
- Integración con múltiples ecosistemas (OpenStack, Kubernetes, virtualización tradicional)
Cada una de estas capacidades por separado es un sistema complejo. Ceph las integra todas. Y aquí está el problema: no puedes entender una sin entender las demás.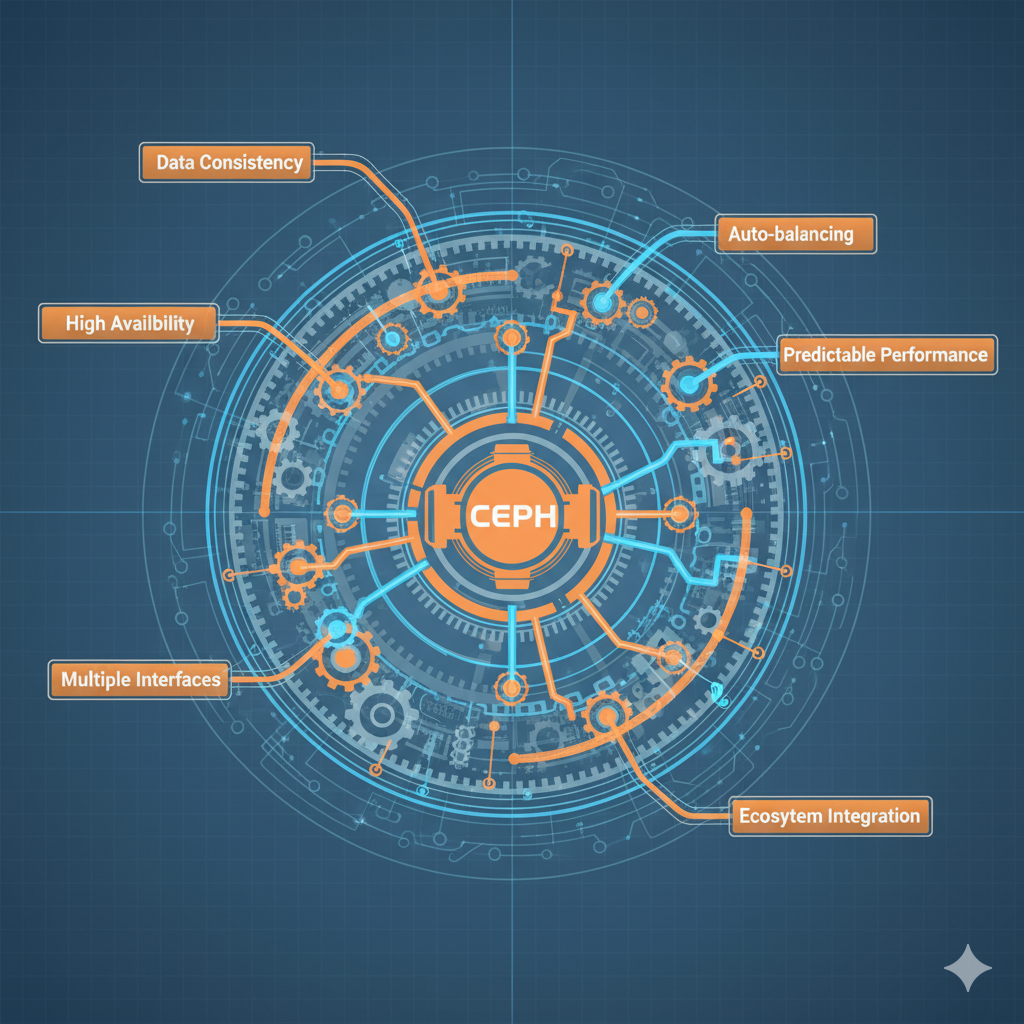
Error #1 de principiantes: Intentar aprender Ceph como si fuera un servicio stateless más. “Configuro, lanzo comandos, y debería funcionar”. No. Ceph es un sistema distribuido con estado compartido, consenso entre nodos, y comportamientos emergentes que solo aparecen bajo carga o fallos. Si no entiendes la arquitectura subyacente, cada problema será un misterio indescifrable.
La documentación asume conocimientos que nadie te enseñó
Lee cualquier página de la documentación oficial de Ceph y encontrarás términos como:
- Placement groups (PGs)
- CRUSH algorithm
- BlueStore / FileStore
- Scrubbing y deep-scrubbing
- Peering y recovery
- OSDs up/down vs in/out
La documentación explica qué son, pero no por qué existen, qué problema resuelven, o cómo interactúan entre sí. Es como intentar aprender a programar empezando por la referencia del lenguaje en lugar de los conceptos fundamentales.
Ejemplo real: Un alumno nos escribió: “He estado 3 meses intentando entender PGs. Leo que ‘son una abstracción lógica’, pero… ¿por qué existen? ¿Por qué no mapear objetos directamente a OSDs?”
Esa pregunta muestra entendimiento profundo. La respuesta (escalabilidad del CRUSH map, granularidad de rebalanceo, overhead de metadatos) requiere entender primero sistemas distribuidos, teoría de hashing consistente, y trade-offs de arquitectura. Nadie te enseña eso antes de soltar ceph osd pool create.
La evolución constante invalida conocimiento
Ceph cambia RÁPIDO. Y no estoy hablando de features opcionales, sino de cambios arquitecturales fundamentales:
- FileStore → BlueStore (2017): Cambia completamente cómo se escribe en disco
- ceph-deploy → ceph-ansible → cephadm (2020): Tres herramientas de deployment diferentes en 5 años
- Luminous → Nautilus → Octopus → Pacific → Quincy → Reef → Squid: 7 versiones major en 7 años, cada una con breaking changes
- Crimson/Seastore (2026+): Reescritura completa del OSD que invalidará gran parte del conocimiento de tuning
Lo que aprendiste hace 2 años sobre tuning de FileStore es completamente irrelevante ahora. Los PGs por pool que calculabas manualmente ahora los gestiona el autoscaler. Las mejores prácticas de networking cambiaron con msgr2.
Error #2 de principiantes (y expertos): Aprender configuraciones de memoria sin entender por qué existen. Vi un administrador que configuraba manualmente PG count con las fórmulas de Luminous… en un cluster Squid con autoscaler activado. El autoscaler lo ignoraba, él no entendía por qué. El contexto histórico importa para saber qué conocimiento está obsoleto.
Cuánto tiempo toma realmente dominar Ceph
Hablemos con números reales basados nuestra experiencia formando administradores:
La progresión realista de aprendizaje
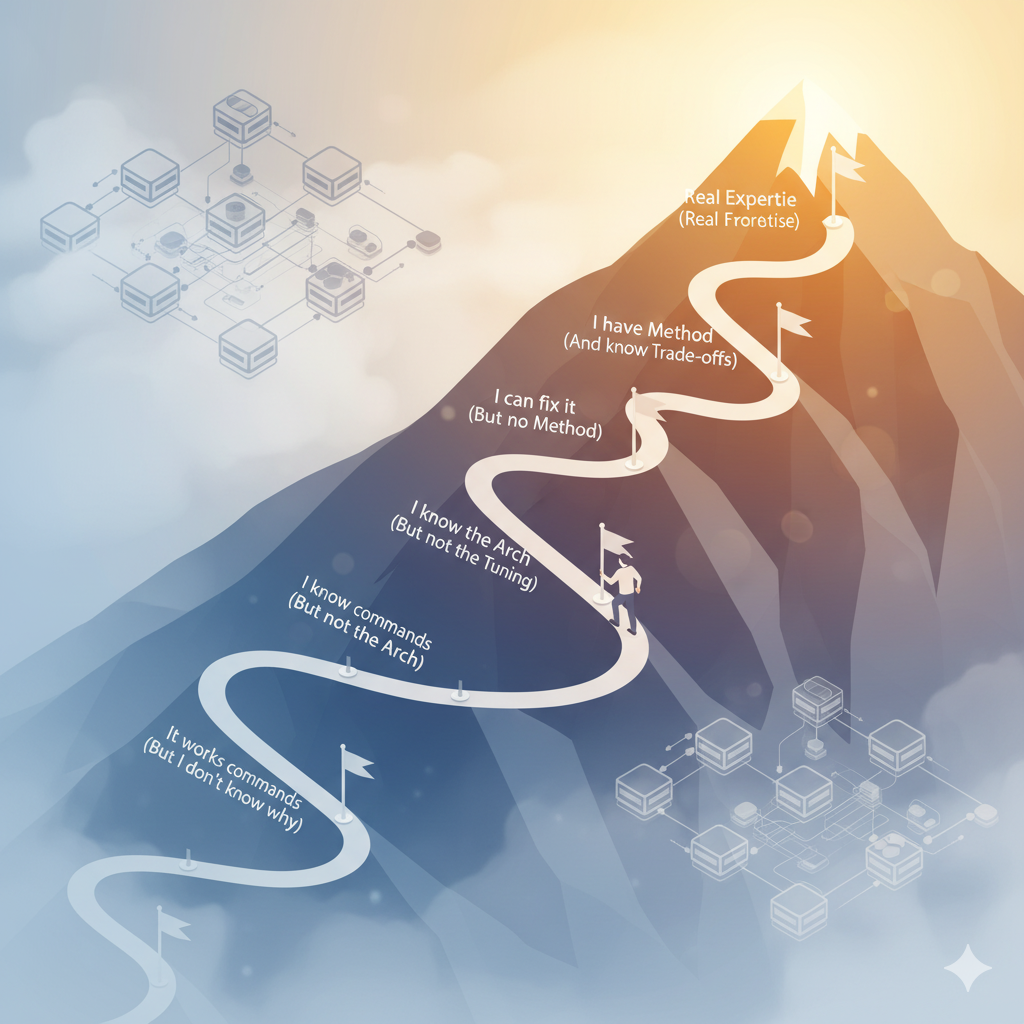
Mes 1-2: “No entiendo nada pero funciona”
Sigues tutoriales. Lanzas comandos ceph osd pool create, ceph osd tree. El cluster funciona… hasta que no. Un OSD se marca como down y entras en pánico porque no sabes diagnosticar.
Síntoma típico: Copias comandos de Stack Overflow sin entender qué hacen. “Lo arreglé” pero no sabes cómo ni por qué.
Mes 3-6: “Entiendo comandos pero no arquitectura”
Ya memorizaste los comandos principales. Sabes crear pools, configurar RBD, montar CephFS. Pero cuando aparece PG 3.1f is stuck in peering, no tienes idea de qué significa “peering” ni cómo solucionarlo.
Síntoma típico: Resuelves problemas por ensayo-error reiniciando servicios hasta que funciona. No hay método, hay suerte.
Mes 6-12: “Entiendo la arquitectura pero no el tuning”
Finalmente entiendes MON/OSD/MGR, el CRUSH algorithm, qué son los PGs. Puedes explicar la arquitectura en una pizarra. Pero tu cluster rinde mal y no sabes si es CPU, red, discos, o configuración.
Síntoma típico: Lees sobre BlueStore tuning, cambias parámetros al azar, no mides antes/después. El performance sigue igual (o peor).
Año 1-2: “Puedo troubleshootear pero sin método”
Ya rescataste algunos clusters. Sabes usar ceph health detail, interpretar estados de PG, recuperar un OSD caído. Pero cada problema es una nueva aventura de 4 horas probando cosas.
Síntoma típico: Puedes arreglar problemas… eventualmente. Pero no puedes predecirlos ni explicar a tu jefe cuánto tardará la solución.
Año 2-3: “Tengo método y entiendo trade-offs”
Diagnosticas sistemáticamente: recoges síntomas, formulas hipótesis, validas con herramientas específicas. Entiendes trade-offs: cuando usar replicación vs erasure coding, cómo dimensionar hardware, cuándo vale la pena el NVMe.
Síntoma típico: Tu respuesta ante problemas es “déjame revisar X, Y y Z” con plan claro. Puedes estimar tiempos de recuperación realistas.
Año 3+: expertise real
Diseñas arquitecturas desde cero considerando workload, presupuesto, SLAs. Haces disaster recovery sin manual. Optimizas BlueStore para cargas específicas. Entiendes el código fuente lo suficiente para debuggear comportamientos raros.
Síntoma típico: Otros admins te llaman cuando un cluster está “imposible”. Tú tardas 20 minutos en identificar el problema que ellos llevan 3 días atacando.
La buena noticia: Puedes acelerar SIGNIFICATIVAMENTE esta progresión con formación estructurada. Un buen curso de 3 días puede condensar 6 meses de ensayo-error. No porque “enseñe más rápido”, sino porque te evita callejones sin salida y malentendidos que consumen semanas.
Los malentendidos típicos que frenan tu aprendizaje
Malentendido #1: “Más hardware = más performance”
He visto clusters con 40 OSDs rindiendo peor que clusters con 12. ¿Por qué? Porque tenían:
- Red pública y cluster en la misma interfaz (saturación garantizada)
- CPU frequency governor en “powersave” (5x degradación en replication)
- PG count totalmente desbalanceado entre pools
- BlueStore cache muy bajo para cargas RGW
La realidad: Ceph performance depende del eslabón más débil. Un single-threaded bottleneck en un MON puede hundir todo el cluster. Más hardware mal configurado solo multiplica el caos.
Malentendido #2: “Erasure coding siempre ahorra espacio”
Un alumno una vez dijo orgulloso: “Pasé todo mi cluster a erasure coding 8+3 para ahorrar espacio”. Le preguntamos: “¿Qué workload tienes?” – “RBD con snapshots frecuentes”. Ups.
Erasure coding con workloads que hacen overwrites pequeños (RBD, CephFS) es TERRIBLE para performance. Y el “ahorro” de espacio se come con los partial stripes y metadata overhead.
La realidad: EC es fantástico para object storage cold data (RGW archives). Es pésimo para block devices con high IOPS. Conocer el workload antes de decidir arquitectura es fundamental.
Malentendido #3: “Si ceph health dice HEALTH_OK, todo está bien”
No. HEALTH_OK significa que Ceph no detectó problemas que él conoce. No detecta:
- Degradación progresiva de discos (SMART warnings)
- Network packet loss intermitente
- Memory leaks en daemons
- Scrubbing que lleva 2 semanas sin completar
- PGs con placement subóptimo que causan hotspots
La realidad: Necesitas monitoring externo (Prometheus + Grafana mínimo) y revisar métricas que Ceph no expone en ceph health. HEALTH_OK es necesario pero no suficiente.
Malentendido #4: “Leo la doc oficial y con eso basta”
La documentación oficial es reference material, no teaching material. Asume que ya entiendes:
- Sistemas distribuidos (Paxos, quorum, consensus)
- Storage fundamentals (IOPS vs throughput, latency percentiles)
- Networking (MTU, jumbo frames, TCP tuning)
- Linux internals (cgroups, systemd, kernel parameters)
Si no traes esa base, la doc te va a confundir más que ayudar.
La realidad: Necesitas recursos adicionales: papers académicos de sistemas distribuidos, blogs de experiencias reales, formación que conecte los puntos que la doc omite.
Errores típicos (que todos cometemos)
Errores de principiantes
No configurar cluster network: La red pública se satura con replicación interna. Performance se hunde. Solución: --cluster-network desde el día 1.
Usar defaults para PG count: En versiones pre-Pacific creabas pools con 8 PGs… para un pool que crecería a 50TB. Imposible rebalancear después. Solución: Autoscaler o calcular bien desde inicio.
No entender la diferencia OSD up/down vs in/out: Sacas un OSD para mantenimiento con ceph osd out y arranca inmediatamente rebalanceo masivo que tarda 8 horas. Querías noout. Ups.
Errores de intermedios
Oversized erasure coding: Configurar 17+3 EC en cluster de 25 nodos. Un nodo se cae y el cluster entra en modo lectura-only porque no hay suficientes OSDs para escribir. Trade-off no entendido.
Ignorar el I/O scheduler: Usar deadline scheduler con NVMe (absurdo). O none scheduler con HDD (desastroso). El scheduler correcto importa 20-30% de performance.
No planificar disaster recovery: “Tenemos replicación 3x, estamos seguros”. Luego un rack entero se cae y pierden quorum de MONs. No practicaron recovery nunca. Pánico.
Errores de expertos (sí, también los cometemos)
Over-tuning: Cambiar 15 parámetros de BlueStore simultáneamente “para optimizar”. Algo rompe. ¿Cuál de los 15 cambios fue? Nadie sabe. Principio: cambiar UNA cosa, medir, iterar.
Confiar demasiado en el conocimiento antiguo: Aplicar técnicas de tuning de FileStore a BlueStore. No funciona porque la arquitectura interna es totalmente diferente. Contexto histórico importa.
No documentar decisiones arquitecturales: Hace 2 años decidiste usar EC 8+2 en cierto pool por razón X. Nadie lo documentó. Ahora un nuevo admin quiere “simplificar” a replication. Desastre evitable con documentación.
La ruta más efectiva para aprender Ceph
Fase 1: fundamentos arquitecturales (40-60 horas)
Antes de tocar un comando, entiende:
- Qué problema resuelve Ceph (vs NAS, vs SAN, vs cloud storage)
- Arquitectura RADOS: cómo funcionan MON, OSD, MGR
- CRUSH algorithm: por qué existe, qué problema resuelve
- Placement groups: la abstracción que hace escalable el sistema
- Diferencia entre pools, PGs, objects, y su mapeo a OSDs
Cómo estudiar esto: No con comandos, sino con diagramas y conceptos. Un buen curso de fundamentos es 100x más efectivo que tutoriales de “deploy en 10 minutos”.
Curso recomendado: Administración Ceph
Nivel: fundamental
3 días intensivos
Programa diseñado específicamente para construir base sólida desde cero. No asume conocimientos previos de storage distribuido.
Fase 2: configuración avanzada y troubleshooting (60-80 horas)
Con fundamentos sólidos, ahora profundizas:
- BlueStore internals: cómo se escriben los datos realmente
- CRUSH rules customizadas para topologías complejas
- Tuning de performance: identificar bottlenecks
- Multi-site RGW para geo-replication
- RBD mirroring para disaster recovery
- Troubleshooting sistemático con método
El objetivo: Pasar de “puedo configurar” a “entiendo por qué configuro así y qué trade-offs estoy haciendo”.
Curso recomendado: Ceph avanzado
Nivel: avanzado
3 días intensivos
Para administradores que ya tienen cluster running pero quieren dominar configuraciones complejas y prepararse para EX260.
Fase 3: operaciones productivas críticas (80-100 horas)
El salto final: de “sé configurar y troubleshootear” a “puedo rescatar clusters en producción a las 3AM”.
- Troubleshooting forense: diagnosticar fallos multi-factor complejos
- Disaster recovery REAL: recuperación de metadata corrupta, journals perdidos
- Performance engineering: optimization a nivel kernel y hardware
- Arquitecturas para cargas específicas: AI/ML, video streaming, compliance
- Security hardening y compliance (GDPR, HIPAA)
- Scaling a petabytes: problemas que solo aparecen a gran escala
El objetivo: Expertise real verificable. Eliminar ese “respeto” (miedo) a escenarios críticos.
Curso recomendado: Ceph production engineering
Nivel: expert
3 días intensivos
El único curso del mercado enfocado 100% en operaciones críticas de producción. No simulaciones – problemas reales.
Práctica continua: el ingrediente no negociable
Aquí está la verdad incómoda: puedes hacer los 3 cursos y seguir sin tener expertise si no practicas. El conocimiento teórico se olvida si no lo aplicas.
La recomendación de SIXE tras cada curso:
- Monta un cluster de práctica (puede ser VMs locales o cloud barato)
- Rompe cosas intencionalmente: mata OSDs, llena discos, satura red
- Practica recovery sin manual: ¿puedes recuperarlo sin Google?
- Mide todo: benchmarks antes/después de cada cambio
- Documenta tus aprendizajes: blog, notas, lo que sea
Pro tip: Los mejores administradores Ceph que conozco mantienen un “lab cluster” permanente donde prueban cosas locas. Algunos incluso tienen scripts que inyectan fallos aleatorios para practicar troubleshooting. Suena extremo, pero funciona.
Conclusión: el camino es largo pero acelerable
Si llegaste hasta aquí, ya estás en el 10% superior de administradores Ceph por pura intención de aprender correctamente. La mayoría abandona cuando se da cuenta de la complejidad real.
Las verdades incómodas que debes aceptar:
- Dominar Ceph toma 2-3 años de experiencia práctica continua. No hay shortcuts mágicos.
- Vas a cometer errores. Muchos. Algunos en producción. Es parte del proceso.
- El conocimiento se deprecia rápido. Lo que aprendes hoy estará parcialmente obsoleto en 18 meses.
- La documentación oficial nunca será tutorial-friendly. Necesitas recursos complementarios.
Pero también las buenas noticias:
- La demanda de expertos Ceph excede masivamente la oferta. Buen momento para especializarse.
- Puedes acelerar 6-12 meses de curva de aprendizaje con formación estructurada que evita callejones sin salida.
- Una vez que “cliquea” la arquitectura fundamental, el resto se construye lógicamente sobre esa base.
- La comunidad es generalmente abierta a ayudar. No estás solo.
Nuestro consejo final después de 10+ años con Ceph: Empieza con fundamentos sólidos, practica constantemente, y no tengas miedo de romper cosas en entornos de prueba. Los mejores administradores que conozco son los que han roto más clusters (en labs) y documentado meticulosamente cada recovery.
Y si quieres acelerar significativamente tu curva de aprendizaje, considera formación estructurada que condense años de experiencia práctica en semanas intensivas. No porque sea más fácil, sino porque te evita los 6 meses que todos perdemos atacando problemas que alguien ya resolvió.
¿Por dónde empezar hoy?
- Si eres principiante total: Curso de administración Ceph
- Si ya gestionas un cluster: Curso de Ceph avanzado
- Si tienes 2+ años y quieres expertise real: Ceph production engineering
O simplemente monta un cluster de 3 VMs, rompe cosas, y aprende troubleshooting. El camino es tuyo, pero no tiene por qué ser solitario.


