Cómo implementar NFS con alta disponibilidad en Ceph usando Ganesha-NFS
Introducción a Ceph y Ceph-Ganesha
Ceph-Ganesha representa una herramienta NFS integrada en CEPH que ofrece potentes funciones de orquestación para conseguir alta disponibilidad y gestión dinámica en clusters Ceph multinodo. En este artículo nos centraremos en la simplicidad declarativa de su despliegue y demuestra sus capacidades de alta disponibilidad.
Ceph es una plataforma de almacenamiento definida por software y de código abierto que proporciona almacenamiento de objetos, bloques y archivos altamente escalable desde un cluster unificado.
La arquitectura de Ceph se basa fundamentalmente en una red distribuida de nodos independientes. Los datos se almacenan mediante OSDs (Object Storage Daemons), se gestionan a través de Monitores y se orquestan por medio de Gestores.
Arquitectura Ceph: fundamentos técnicos
El Sistema de Archivos Ceph (CephFS) es un sistema de archivos compatible con POSIX que se asienta sobre esta infraestructura, proporcionando un espacio de nombres distribuido y tolerante a fallos. Para los administradores de sistemas, Ceph supone una alternativa sólida a las matrices de almacenamiento tradicionales, ya que ofrece una plataforma única y resistente que puede crecer linealmente con la incorporación de hardware básico.
Las capacidades de autorreparación y autogestión son ventajas clave, reduciendo la sobrecarga operativa.
NFS Ganesha en Ceph: características distintivas
NFS Ganesha funciona como un servidor NFS de código abierto que actúa como pasarela en el espacio de usuario, una distinción clave respecto a los servidores NFS convencionales que residen en el núcleo del sistema operativo. Esta decisión de diseño fundamental proporciona un entorno de servicio más robusto y estable. Los errores en un demonio de espacio de usuario tienen muchas menos probabilidades de provocar un fallo catastrófico del sistema, una ventaja crucial para un punto final de servicio crítico. La arquitectura de Ganesha también está diseñada para ofrecer la máxima compatibilidad, ya que admite una gama completa de protocolos NFS, desde NFSv3 hasta NFSv4.2, lo que garantiza que puede atender a una base de clientes diversa.
La verdadera innovación de Ganesha reside en su capa de abstracción del sistema de archivos, o FSAL. Esta arquitectura modular desacopla la lógica del protocolo NFS del almacenamiento subyacente. Para un entorno Ceph, el módulo FSAL_CEPH resulta fundamental, ya que permite a Ganesha actuar como un sofisticado cliente Ceph. Esto significa que los administradores pueden proporcionar una interfaz NFS consistente a los clientes, al tiempo que se benefician de toda la potencia y escalabilidad del cluster Ceph, sin exponer directamente la infraestructura Ceph subyacente. Si quieres profundizar en estas tecnologías puedes acceder al curso de despliegue y administración básica de Ceph que ofrecemos en SIXE.

Integración de Cephadm: despliegue declarativo simplificado
La integración de Ganesha con el orquestador Ceph (cephadm) eleva su despliegue desde una tarea manual específica de cada host hasta una elegante operación a nivel de cluster. Esta asociación permite un enfoque declarativo de la gestión de servicios, donde un único comando puede gestionar todo el ciclo de vida del servicio Ganesha.
Para cualquier servicio de misión crítica, la principal preocupación de los administradores de sistemas es garantizar la continuidad del negocio. Las interrupciones no planificadas pueden provocar pérdidas significativas de datos, reducción de la productividad y daños reputacionales. La Alta Disponibilidad (HA) constituye el principio arquitectónico que aborda esta preocupación eliminando los puntos únicos de fallo. Para un servicio NFS, esto significa que si un nodo servidor falla, otro nodo puede asumir sus funciones de manera transparente. Esto proporciona tranquilidad a los administradores y permite realizar mantenimiento planificado sin afectar al usuario final. En el caso de Ceph, su naturaleza distribuida inherente complementa perfectamente un servicio NFS de HA, ya que el almacenamiento subyacente es resistente por diseño a los fallos de los nodos.
Preparación del almacenamiento CephFS para Ganesha
Un despliegue exitoso de Ganesha comienza con la preparación adecuada del almacenamiento CephFS subyacente.
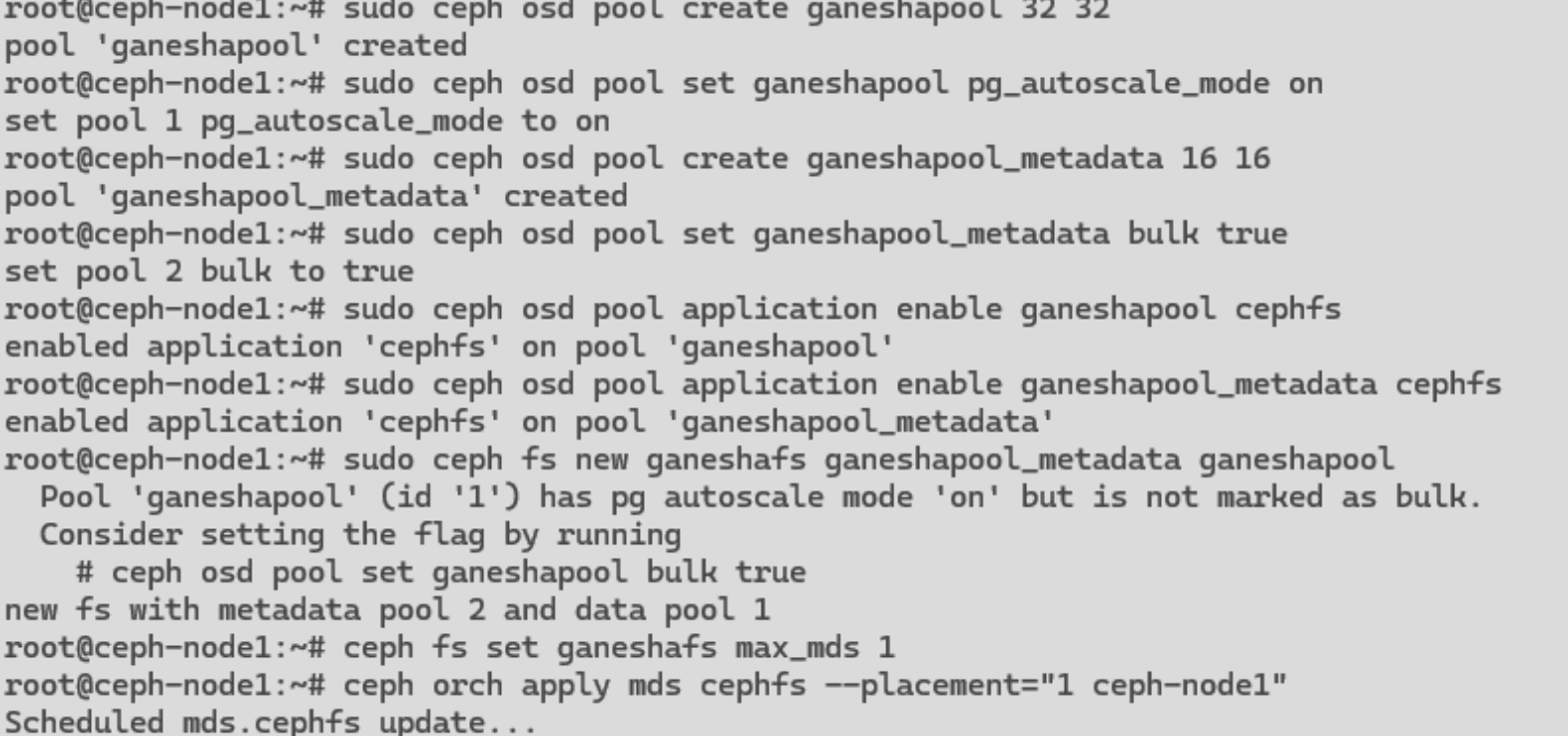
Crear un pool dedicado para datos NFS Ganesha con autoescalado activado
# sudo ceph osd pool create ganeshapool 32 32
# sudo ceph osd pool set ganeshapool pg_autoscale_mode on
Crear un pool de metadatos, marcado como bulk para un comportamiento optimizado
# sudo ceph osd pool create ganeshapool_metadata 16 16
# sudo ceph osd pool set ganeshapool_metadata bulk true
Vincular los pools a un nuevo sistema de archivos CephFS
# sudo ceph osd pool application enable ganeshapool cephfs
# sudo ceph osd pool application enable ganeshapool_metadata cephfs
# sudo ceph fs new ganeshafs ganeshapool_metadata ganeshapool
# ceph fs set ganeshafs max_mds 3
# ceph orch apply mds cephfs --placement="3 ceph-node1 ceph-node2"
Despliegue del servicio Ceph NFS Ganesha
Una vez establecidos los cimientos del almacenamiento, el despliegue de Ganesha puede realizarse tanto con archivos .yaml como con comandos CLI de orquestación sencillos. El comando ceph orch apply constituye una instrucción potente al orquestador, indicándole que garantice el estado deseado del servicio NFS. Al especificar un recuento de ubicaciones y enumerar los hosts del cluster, los administradores se aseguran de que se ejecutará un demonio Ganesha en cada nodo designado, un paso crítico para conseguir un servicio resistente y de alta disponibilidad.
Desplegar el servicio NFS de Ganesha en los tres hosts especificados
# sudo ceph orch apply nfs myganeshanfs ganeshafs --placement="3 ceph-node1 ceph-node2 ceph-node3"
Este comando único inicia un despliegue complejo y multifacético. El orquestador extrae las imágenes de contenedor necesarias, configura los demonios y los distribuye entre los hosts especificados. Esto contrasta claramente con las instalaciones manuales host por host, mostrando la potencia de la orquestación centralizada. Estos escenarios los tratamos detalladamente en el curso de administración avanzada de Ceph que ofrecemos, donde se cubre paso a paso la orquestación con cephadm y las configuraciones de HA.
Capacidades avanzadas: exportaciones dinámicas y resistencia del servicio
Una vez que el servicio Ganesha está en funcionamiento, su potencia se revela aún más a través de sus capacidades de gestión dinámica de exportaciones. En lugar de editar archivos de configuración estáticos, los expertos pueden crear, modificar y eliminar exportaciones NFS sobre la marcha mediante una serie de comandos sencillos. Esta funcionalidad resulta inestimable en entornos dinámicos donde las necesidades de almacenamiento cambian rápidamente.
Crear una nueva exportación para hacer accesible el sistema de archivos CephFS
# sudo ceph nfs export create cephfs myganeshanfs /ganesha ganeshafs --path=/

El verdadero valor de este despliegue distribuido reside en la resistencia de sus servicios. El orquestador Ceph supervisa constantemente la salud de los demonios Ganesha. Si falla un host, el orquestador detectará automáticamente la pérdida y tomará medidas para garantizar que el servicio siga disponible. Este proceso automatizado de conmutación por error proporciona un alto grado de transparencia a los clientes, haciendo que Ganesha pase de ser una simple pasarela a convertirse en un servicio de verdadera alta disponibilidad. Su arquitectura está construida para resistir interrupciones, convirtiéndola en una parte indispensable de una estrategia de almacenamiento robusta.
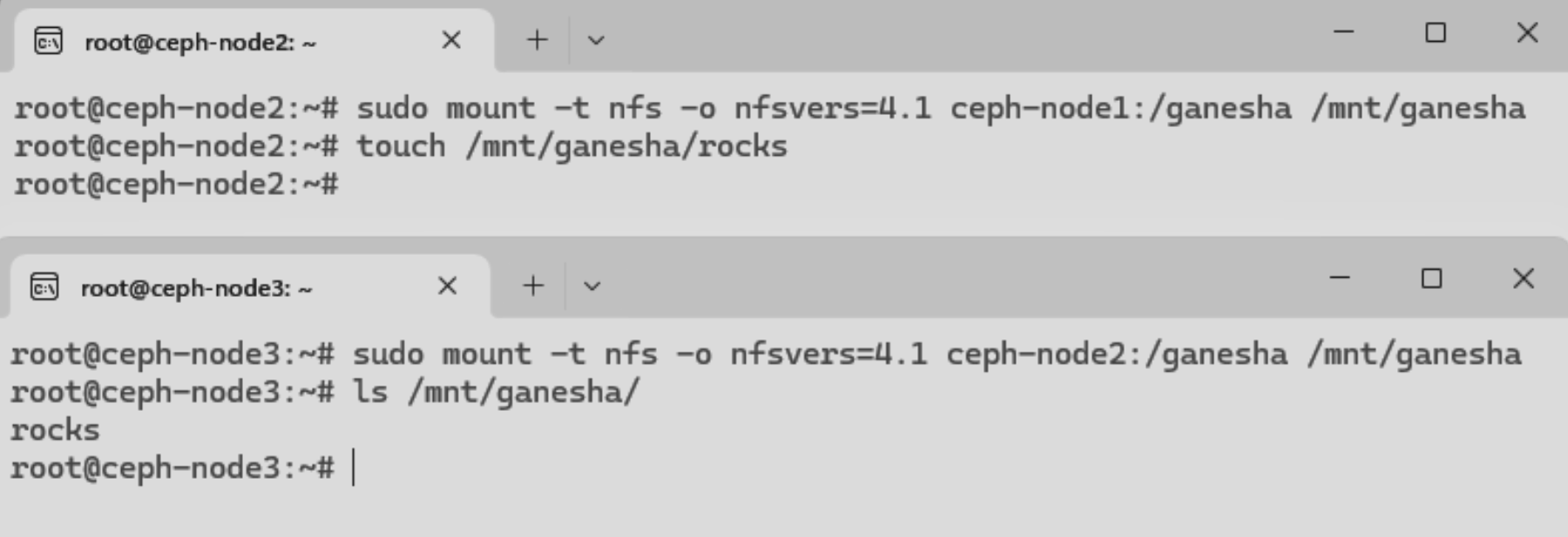
Ejemplo práctico
Supongamos que disponemos de un cluster con 3 nodos preparados para Ganesha. Esto significa que se pueden exportar exitosamente los filesystems ceph subyacentes del nodo 1 al nodo 2 y del nodo 2 al nodo 3, o en cualquier configuración deseada.
Conclusión: por qué Ceph-Ganesha resulta esencial para el almacenamiento moderno
NFS Ganesha trasciende el concepto de simple pasarela para convertirse en un componente crítico para integrar los servicios de archivos tradicionales con el almacenamiento moderno y escalable. Aprovechando la orquestación de línea de comandos de cephadm, los administradores pueden desplegar un servicio altamente disponible, resistente y gestionable dinámicamente. El proceso constituye un testimonio del poder de la gestión declarativa de infraestructuras, simplificando lo que de otro modo sería una tarea compleja. El diseño arquitectónico de Ganesha, combinado con la potencia del orquestador Ceph, lo convierte en una solución perfecta para satisfacer los exigentes requisitos de almacenamiento de los entornos híbridos actuales. Precisamente por eso, en SIXE no sólo se ofrece formación sobre Ceph, sino también apoyo especializado para que las empresas puedan mantener la estabilidad de sus infraestructuras de producción.
? Soporte técnico Ceph
? Curso de despliegue y administración básica en Ceph
? Curso de administración avanzada y resolución de problemas de Ceph